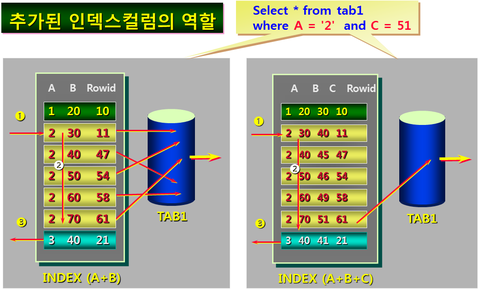
양쪽 ACCESS 횟수는 비슷하지만 왼쪽의 경우는 TABLE ACCESS가 일어났지만, 오른쪽은 INDEX ACCESS 만으로 답을 찾을 수 있다.
INDEX COLUMN 순서 결정
1. 항상 사용하는가 ?
2. 항상 '='로 사용되는가 ?
또는'='로 사용되게 할 수 있느냐 ? LIKE, BETWEEN => IN ( ... ) 조건으로 바꿀수 있느냐 ?
3. 분포도가 좋은 COLUMN 우선 (OLTP의 경우 중요)
4. SORT 를 대신해서 INDEX로 사용 (BATCH SYSTEM의 경우는 분포도보다 더 우선시 될 수도 있음)
5. 어떤 COLUMN을 추가 ? (후보선수)
Table Access 예방
Optimizer의 판단 MISS 예방 ( A-B INDEX 와 C-D INDEX의 경합일때 항상 A-B를 사용했으면 좋겠을 경우, C-D-E로 INDEX 수정)
INDEX 선정 절차
1. 해당 TABLE의 ACCESS 유형 조사 : WHERE 절, 불필요한 JOIN은 없는지...
2. 대상 COLUMN의 선정 및 분포도 분석
3. 반복수행되는 액세스경로(Critical Access Path)의 해결 : LOOP 안에서 사용되는 SQL문...
4. CLUSTERING 검토
5. INDEX COLUMN의 조합 및 순서의 결정
6. 시험생성 및 TEST
7. 수정이 필요한 APPLICATION 조사 및 수정 : SQL문들 전부 다 수정
8. 일괄 적용
ACCESS 유형의 조사 (설계단계)
1. 반복 수행되는 ACCESS 형태를 찾는다.
2. 분포도가 아주 양호한 COLUMN을 찾아 ACCESS 유형을 찾는다.
3. 자주 넓은 범위의 조건이 부여되는 경우를 찾는다. : CLUSTER 검토
4. 자주 조건절에 사용되는 COLUMN들의 ACCESS 유형을 찾는다.
5. 자주 경합되어 사용되는 경우를 찾는다.
6. SORT의 유형을 조사한다.
7. 일련번호를 부여하는 경우를 찾는다. : PK Level로 만들어주면 좋다.
8. 통계자료 추출을 위한 ACCESS 유형을 조사한다.
INDEX 선정기준
1. 분포도가 좋은 COLUMN은 단독으로 생성하여 활용도 향상
2. 자주 조합되어 사용되는 경우는 결합INDEX 생성
3. 각종 ACCESS 경우의 수를 만족할 수 있도록 INDEX 간의 역할 분담
4. 가능한 수정이 빈번하지 않은 COLUMN
5. Primary Key 및 Foreign Key (JOIN의 연결고리가 되는 COLUMN)
6. 결합 INDEX의 COLUMN 순서 선정에 주의
7. 반복수행(LOOP 내) 되는 조건은 가장 빠른 수행속도를 내게 할 것
8. 실제 조사된 ACEESS 종류르 토대로 선정 및 검증
INDEX 고려사항
1. 새로 추가된 INDEX는 기존 ACCESS 경로에 영향을 미칠 수 있음 : 기존에 잘 돌아가던 SQL문들을 망가트릴수 있음
2. 지나치게 많은 INDEX는 오버헤드를 발생 : 20개의 INDEX가 있는 TABLE에서도 기껏 사용되는 INDEX는 4개 정도 ?
3. 넓은 범위를 INDEX로 처리시 많은 오버헤드 발생 : 차라리 FULL-SCAN이 빠름
4. OPTIMIZER를 위한 통계데이터를 주기적으로 갱신 : Cost-based 이용시
5. INDEX 개수는 TABLE의 사용형태에 따라 적절히 생성
OLTP : INDEX 최소화, DW : 많아도 괜찮음
6. 분포도가 양호한 COLUMN도 처리범위에 따라 분포도가 나빠질 수 있음
특정 DATA가 90% 같은 경우 나머지 DATA에 대해서만 INDEX-SCAN, 해당 DATA는 FULL-SCAN이 유리함
SELECT * FROM XX WHERE :v1 = '100' AND corp_id || '' = :v1
UNION ALL
SELECT * FROM XX WHERE :v1 <> '100' AND corp_id = :v1
위와 같이 각각 서로 동시에 참이되지 않을 조건으로 만든후 합집합을 이용하면 된다.
하지만 실무에서는 LIKE 를 이용하여 간편한 SQL문을 많이 사용한다.
SELECT * FROM XX WHERE corp_id LIKE :v1 || '%' AND stdt_id LIKE :v2 || '%';
업체ID, 수강생ID 중 둘 중 하나만 입력해도 답이 나오는 만능 SQL문이다.
하지만 위의 SQL문의 실행계획은 두 ID중 분포도가 좋은 것으로 하나로 정해진다.
만약 corp_id로 INDEX를 쓰기로 정해졌는데, stdt_id 만 입력되었을 경우 해당 INDEX를 거의 FULL-SCAN 하는 일이 발생하게 된다.
SQL을 제대로 아는 사람은 LIKE의 사용을 되도록이면 피한다.
7. INDEX 사용원칙을 준수해야 INDEX가 사용되어짐 : 좌변가공, 부정비교, NULL 비교 등등...
8. JOIN 시 INDEX가 사용여부에 주의
추가된 INDEX가 미치는 영향
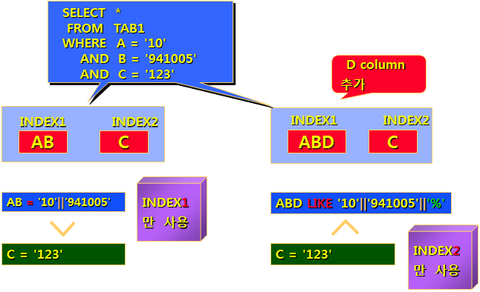
왼쪽의 경우는 INDEX1이 결합도가 더 좋아서 해당 INDEX 만 사용되었는데,
오른쪽과 같이 INDEX를 수정하면 INDEX2가 더 정확하게 되어서 INDEX2만 사용하게 된다.
즉, 그 전과는 수행시간차이가 많이 날수가 있다.
분포도 차이가 심한 INDEX의 경우
INDEX-SCAN의 경우 전체 범위의 10%가 넘는 DATA에 대해서는 FULL-SCAN에 비해 더 느리다.
그러므로 많은 비중을 차지하는 것에 대해서는 FULL-SCAN이 더 현명하다.
그럼 많은 비중을 차지하는 것에 대해서만 INDEX에 집어 넣지 않을수만 있다면 ?
INDEX 용량을 줄여서 다른 DATA의 INDEX-SCAN의 속도를 높여줄 뿐더러, FULL-SCAN에 대해서 일부러
SQL문을 수정하여 Supressing 하지 않아도 된다.
KEY 값이 NULL인 경우 해당 KEY에 대해서는 INDEX에서 제외시킨다.
많은 비중을 차지하는 값은 NULL로 처리하면 된다.
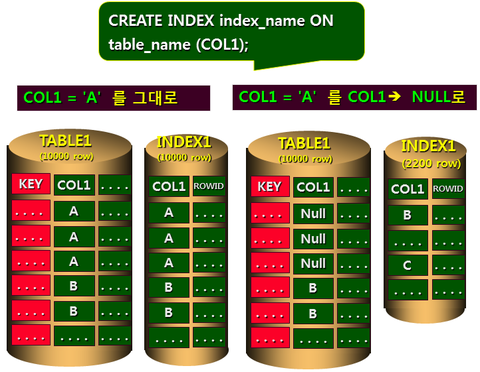
그 값에 대해서는 IS NULL 로 비교를 하여 출력시에는 SELECT NVL(ID,'101') ... 이런식으로 처리하면 된다.
INDEX REBUILD
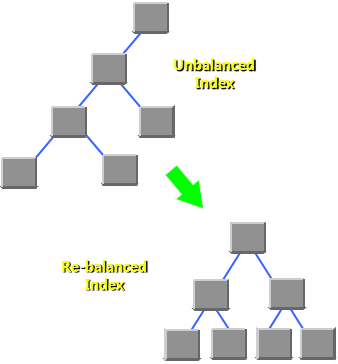
INDEX를 오랫동안 사용하면서 UPDATE, DELETE 가 일어나다보면 Unbalanced Tree 구조를 띄게 된다. 그럴 경우 각 값을 찾아가는 시간이 천차만별이되며 전체적으로 더 느려지게 된다. 과거에는 INDEX를 삭제 후 새로 생성하였는데, 이러면 그 동안 업무를 볼 수가 없게 되어 주로 아무도 일하지 않는 야근시간이나 주말, 명절에 DBA분들이 남아서 많이 했었다. 이제는 INDEX REBUILD 기능이 생겨서 그럴 필요 없다. REBUILD 하는 방법은 아래와 같다.
ALTER INDEX index_name REBUILD UNRECOVERABLE PARALLEL 10;
* 현존하는 INDEX를 지우지않고 그것을 활용하여 재생성한다.
* DDL Lock을 발생시키지 않아서 업무를 중단시키지 않고 작업이 가능하다.
* 병렬처리를 지원한다.
* Direct database reads and writes
* Multi-Block을 비동기적으로 I/O 한다.
* REDO LOG 에 쓰지 않도록 설정이 가능하다.
BITMAP INDEX

전통적인 INDEX와는 다른 모양의 INDEX이다. KEY값들을 BITMAP 형식으로 분석하여 저장하는 방식이다.
만드는 법은 아래와 같다.
CREATE BITMAP INDEX prod_color ON prod(color);
* 새로운 형태의 IDEX이며 분포도가 낮은 COLUMN에 효과적이다.
* 전통전인 B*Tree INDEX의 단점을 해소 (OR, NOT, NULL 등의 비교에서의 INDEX 활용 가능)
* I/O의 획기적인 감소
* Block-Level Locking 이라는게 단점이다. (Row-Level Lock은 B*Tree INDEX만 가능)
* DW (데이터웨어하우징)에 적당하다. (OLTP 시스템에서는 오히려 안좋다.)


댓글 없음:
댓글 쓰기