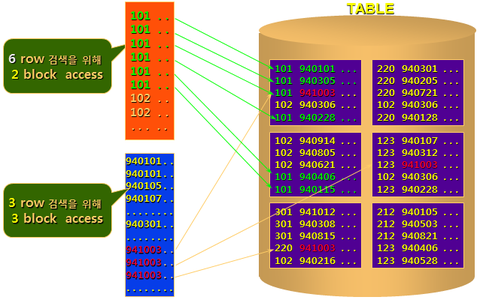
CLUSTERING FACTOR
만약 TABLE에 부서번호, 주문일자 의 정보를 저장하고 있는 Table이 있을 경우 기본적을 부서번호-주문일자 순으로 Data를 넣지만, UPDATE, DELETE 작업등으로 인하여 완벽한 Sorting이 안되어 있다. 이럴 경우 특정 부서번호의 6개의 ROW를 읽기위해서는 2개의 BLOCK을 ACCESS 하면 되지만 특정 주문일자의 3개의 ROW를 읽기 위해서는 3개의 BLOCK을 ACCESS 해야한다.
- CLUSTERING를 활용하면 DB Block Buffer Hit Ratio에 영향을 줘서 성능을 크게 향상 시킬수 있다.
CLUSTERING TABLE
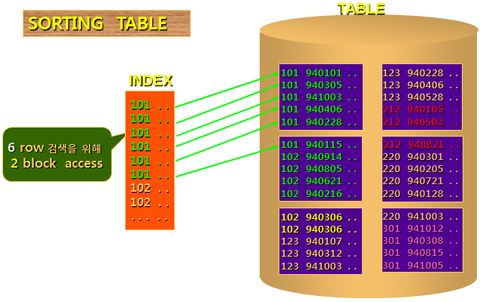
- CLUSTERING TABLE을 생성하면 CLUSTER KEY 순으로 DATA를 DISK에 저장한다.
- CLUSTERING INDEX는 해당 KEY의 시작주소를 가지고 있다.
 (INDEX는 KEY의 모든 ROWID를 저장하고 있다.)
(INDEX는 KEY의 모든 ROWID를 저장하고 있다.)
SORTING TABLE
 대부분 현업에서 CLUSTER를 사용하는 곳은 거의 없다. 성능상 큰 문제가 있는데, CLUSTER만 도입하면 엄청 빨라질 것으로 예상되지만 CLUSTER를 사용한다고 결정하기는 쉽지 않다. 왜냐면 CLUSTER는 INDEX와는 그 차원이 다르다. INDEX가 시속 100 km로 달릴수 있는 자동차라면 CLUSTER는 시속 1000 km로 날라다니는 비행기이다. CLUSTER를 생성하면 해당 TABLE을 사용하는 모든 SQL문의 실행계획이 바뀌어버려서, 과거 생성한 INDEX에 최적화된 SQL문들의 실행계획이 완전 바뀌어 버려서 오히려 성능이 안좋아질수도 있기 때문이다. CLUSTER를 도입하면 프로그램 전체를 다 수정해야 한다. 그래서 그 대안으로 SORTING TABLE을 생각 할 수 있다. CLUSTER를 만드는 것이 아니라 TABLE의 DATA를 순서대로 저장하여 CLUSTER를 사용한 듯한 Hit Ratio를 보장받을 수 있도록 하는 방법이다.
대부분 현업에서 CLUSTER를 사용하는 곳은 거의 없다. 성능상 큰 문제가 있는데, CLUSTER만 도입하면 엄청 빨라질 것으로 예상되지만 CLUSTER를 사용한다고 결정하기는 쉽지 않다. 왜냐면 CLUSTER는 INDEX와는 그 차원이 다르다. INDEX가 시속 100 km로 달릴수 있는 자동차라면 CLUSTER는 시속 1000 km로 날라다니는 비행기이다. CLUSTER를 생성하면 해당 TABLE을 사용하는 모든 SQL문의 실행계획이 바뀌어버려서, 과거 생성한 INDEX에 최적화된 SQL문들의 실행계획이 완전 바뀌어 버려서 오히려 성능이 안좋아질수도 있기 때문이다. CLUSTER를 도입하면 프로그램 전체를 다 수정해야 한다. 그래서 그 대안으로 SORTING TABLE을 생각 할 수 있다. CLUSTER를 만드는 것이 아니라 TABLE의 DATA를 순서대로 저장하여 CLUSTER를 사용한 듯한 Hit Ratio를 보장받을 수 있도록 하는 방법이다.
한 가지 예를 들어보겠다.
보험회사 시스템이 하나 있다. 이 시스템은 GIS 기반의 서비스를 직원들에게 제공한다.
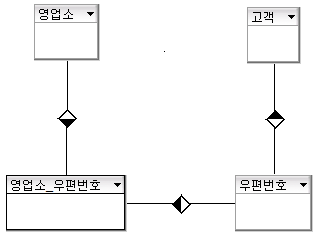
각 대리점 별로 관할 구역이 있고, 각 구역별로 고객들을 관리한다. 대리점별로 당연 구역들은 겹칠 수가 있다. 이것을 최적화한 ERD를 아래와 같이 표현이 가능하다.
한 영업소에서 관리하는 고객 정보를 조회하는데 100여명 밖에 나오지 않는데도 조회시간이 3초가 넘는 시간이 걸렸다. 분명 고객에는 ZIP-CODE로 INDEX가 잡혀있는데도 그랬다. 왜 느릴까 ? 고객 TABLE의 PK는 당연 고객ID가 될 것이다. 하지만 대부분의 JOIN 조건은 ZIP-CODE 이므로 고객ID의 PK가 과연 효율적일까 ? 특정 지역에 사는 100명의 고객을 읽기위해서 100개의 Block을 Random-Single I/O를 한다면 당연 좋은 성능을 기대하기 힘들다. 대부분의 GIS 시스템은 ZIP-CODE 순으로의 ACCESS가 많다. 고객의 PK는 고객ID로 하더라도 물리적인 저장은 ZIP-CODE, 고객ID 순으로 한다면 Hit-Ratio가 훨씬 좋아져서 성능이 향상될 것이라고 생각할 수 있다.
그렇다고 이미 오랫동안 사용중인 SYSTEM에 CLUSTER를 도입하는 것은 위험부담이 너무 크다. 그래서 고객 Table을 물리적으로 ZIP-CODE, 고객ID 순으로 정렬을 해서 넣는 방법을 선택했다.
이런식으로 약간의 편법을 이용하여 DATA 자체를 SORTING 하여 저장하는 것을 SORTING TABLE 이라고 한다.
CLUSTER 의 구조
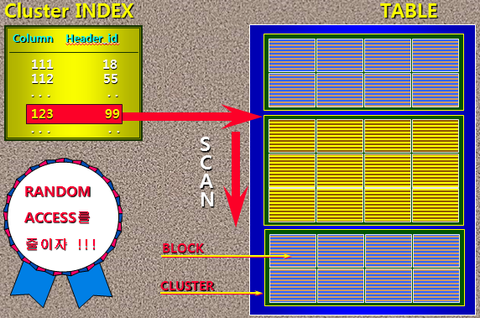
CLUSTER INDEX는 KEY와 그 시작주소만을 가지고 있다.
CLUSTERING TABLE 은 각 CLUSTER KEY 별로 물리적인 CLUSTER로 관리를 한다. CLUSTER는 BLOCK 들의 집합으로 CLUSTER 생성시 그 크기를 지정할수가 있다.
하나의 KEY의 모든 DATA는 CLUSTER에 저장된다. 그러므로 CLUSTER의 크기가 너무 크면, DATA의 수가 적은 KEY에 대해서는 많은 공간이 낭비가 될 것이며, 그렇다고 CLUSTER 크기를 너무 작게 한다면 같은 KEY에 대해서 여기저기에 쪼가리들로 연결되야 하므로 그 효율성이 줄어들 것이다.
CLUSTER 생성시 CLUSTER KEY SIZE PARAMETER가 정말 중요하다. 이 SIZE는 면적으로 생각해야 한다.
1개의 ROW DATA의 평균크기 * KEY별 평균 DATA 수 를 계산해서 Overhead 10% 정도를 추가하여 생성하는게 가장 적당하다.
MULTI-TABLE CLUSTER
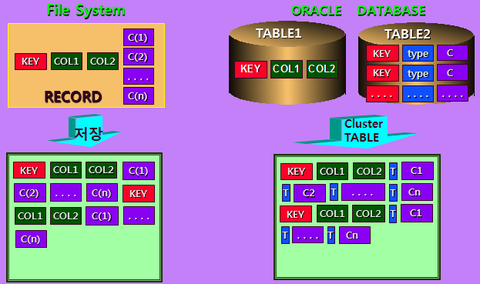
전통적인 FILE SYSTEM의 경우는 각 KEY 별로 DATA를 연속적으로 보관하는 경우가 많다. 이것을 DATABASE MODEL로 변경하면서 정규화 1공식. 모든 DATA는 원자화하여 저장한다는 공식을 적용하면서 오른쪽 그림과 같이 2개의 TABLE로 나눠서 저장하게 된다. 하지만 실제로 사용할때는 2개의 TABLE을 늘 JOIN으로 사용한다. (예를 들어서 주문 + 주문내역) 이럴 경우 TABLE은 2개로 나눠져 있더라도 DISK에 같은 공간에 연속적으로 저장되어 있다면 성능을 향상 시킬수 있다. 이때 MULTI-TABLE CLUSTER를 활용하면 된다.
- SELECT 시 엄청난 성능 향상이 기대가 가능하다.
- 하지만 OLTP 환경의 UPDATE, DELETE 등에 대해서는 엄청난 Overhead가 일어나므로 오히려 전체적인 성능을 저하시킬수 있다.
- 절대로 UPDATE, DELETE가 일어나지 않는 환경이라면 도입을 고려해 볼만하다.
* SINGLE-TABLE CLUSTER : INDEX RANGE 때문에 부담이 될 경우에 유용함
* MULTI-TABLE CLUSTER : 정규화에 의해 어쩔수 없이 분할된 TABLE에서 항상 JOIN되기 때문에 물리적으로 한 공간에 둘때 유용함
CLUSTER란 ?
1. 지정된 COLUMN의 순서대로 ROW를 물리적으로 저장시키는 방법이다.
2. 하나 혹은 그 이상의 TABLE을 같은 CLUSTER내에 저장이 가능하다. (MULTI-TABLE CLUSTER)
3. ACCESS 기법이 아니라 ACCESS 효율성을 위한 물리적 저장기법이다.
4. SELECT의 효율을 높여주나 INSERT, UPDATE, DELETE의 부하가 증가된다. (INDEX의 2,3배이상 느림)
5. 분포도가 높을수록 오히려 유리하다. (INDEX의 반대 : INDEX의 단점을 해결 5~7배이상 빠름)
6. 분포도가 넓은 TABLE의 CLUSTERING은 오히려 절약공간이 절약된다. (INDEX에 비해서 KEY의 시작만 가짐)
CLUSTER 선정기준
1. 6 Block 이상의 TABLE
2. 다량의 범위를 자주 ACCESS 하는 경우
3. INDEX를 사용한 처리가 부담이 되는 넓은 분포도를 가지는 경우
4. 여러 개의 TABLE이 비번한 JOIN을 일으킬 때
5. 반복COLUMN이 정규화 작업에 의해 어쩔 수 없이 분할된 경우
6. UNION, DISTINCT, ORDER BY, GROUP BY가 빈번한 COLUMN이면 고려해 볼것 (주로 통계 분석 시스템)
7. 수정이 자주 발생하지 않는 COLUMN
8. 처리범위가 넓어 문제가 발생되는 경우는 SINGLE-TABLE CLUSTERING
9. JOIN이 많아 문제가 발생되는 경우는 MULTI-TABLE CLUSTERING
CLUSTER 고려사항
01. DATA 처리(INSERT, UPDATE, DELETE)에 Overhead 발생 주의
02. INDEX로 충분한 범위는 CLUSTERING 효과가 없음 (Key당 10건 정도 ?)
03. CLUSTER KEY는 수정이 빈번하지 않을 것
04. 각종 ACCESS 형탸에 대해 INDE와 적절한 역할 분담
05. CLUSERING은 기존 INDEX의 수를 감소시킴 (전체적인 INDEX를 재구성 해야함)
06. CLUSTER SIZE PARAMETER가 중요
07. CLUSTER KEY 별로 ROW 수의 편차가 심하지 않을 것
08. CLUSTER에 DATA 입력시 ROW가 적은 TABLE부터 실시할 것
09. CLUSTERING TABLE에 JOIN시 ROW 수의 역순으로 FROM절에 기술할 것 (FROM 절 잴 뒷쪽에)
10. CLUSTERING KEY를 첫번째로 하는 INDEX는 생성하지 말 것
INDEX vs CLUSTER
- INDEX : 해당 INDEX 만큼의 TABLE ACCESS를 반복한다.
- CLUSTER : CLUSTER HEADER를 찾아서 한번에 SCAN
CLUSTER 생성 예제
ANALYZE TABLE MECHUL2T COMPUTE STATISTICS;SELECT AVG_ROW_LEN FROM USER_TABLES WHERE TABLE_NAME = 'MECHUL2T';
SELECT AVG(COUNT(*)) FROM MECHUL2T GROUP Y SALEDATE;
위와 같이 하면 하루 종일 걸린다. 전체 TABLE을 할게 아니라 표본만 몇개 만들어서 하는게 효율적이다.
CREATE CLUSTER MECHUL2# (SALEDATE CHAR(6))
PCTFREE 10 PCTUSED 60 SIZE 3300;
CREATE INDEX MECHUL2#X ON CLUSTER MECHUL2#;
이렇게 해서 CLUSTER TABLE 을 만든다.
RENAME MECHUL2T TO MECHULCT;
이제 테이블 이름을 바꿔준 다음에
CREATE TABLE MECHUL2T (
SALENO VARCHAR2(6) NOT NULL ...
) CLUSTER MECHUL2# (SALEDATE);
TABLE 을 만들면서 TABLE SPACE 대신에 CLUSTER로 지정한다.
INSERT INTO MECHUL2T SELECT * FROM MECHULCT;
DROP TABLE MECHULCT;
CREATE INDEX ...
이제 할일을 해주면 된다.
속도비교

각각의 DATA 들에 대해서 CLUSTER 이용, FULL-SCAN, INDEX-SCAN 시의 속도이다.
CLUSTER 사용 예제

CLUSTER는 Driving 조건으로 사용되어야지 CHECK 조건으로 사용되면 INDEX-SCAN보다 더 느릴수 있다.
CLUSTER가 Driving 될 수 있도록 다른 조건의 다리를 톡 부러트려버려야 된다.
CLUSTER 사용시는 반드시 실행계획을 확인해서 원하는 방향되로 가고 있는지 확인하고,
그렇지 않을때는 수정해 주어야 한다.
만약 TABLE에 부서번호, 주문일자 의 정보를 저장하고 있는 Table이 있을 경우 기본적을 부서번호-주문일자 순으로 Data를 넣지만, UPDATE, DELETE 작업등으로 인하여 완벽한 Sorting이 안되어 있다. 이럴 경우 특정 부서번호의 6개의 ROW를 읽기위해서는 2개의 BLOCK을 ACCESS 하면 되지만 특정 주문일자의 3개의 ROW를 읽기 위해서는 3개의 BLOCK을 ACCESS 해야한다.
- CLUSTERING를 활용하면 DB Block Buffer Hit Ratio에 영향을 줘서 성능을 크게 향상 시킬수 있다.
CLUSTERING TABLE
- CLUSTERING TABLE을 생성하면 CLUSTER KEY 순으로 DATA를 DISK에 저장한다.
- CLUSTERING INDEX는 해당 KEY의 시작주소를 가지고 있다.
(INDEX는 KEY의 모든 ROWID를 저장하고 있다.)SORTING TABLE
대부분 현업에서 CLUSTER를 사용하는 곳은 거의 없다. 성능상 큰 문제가 있는데, CLUSTER만 도입하면 엄청 빨라질 것으로 예상되지만 CLUSTER를 사용한다고 결정하기는 쉽지 않다. 왜냐면 CLUSTER는 INDEX와는 그 차원이 다르다. INDEX가 시속 100 km로 달릴수 있는 자동차라면 CLUSTER는 시속 1000 km로 날라다니는 비행기이다. CLUSTER를 생성하면 해당 TABLE을 사용하는 모든 SQL문의 실행계획이 바뀌어버려서, 과거 생성한 INDEX에 최적화된 SQL문들의 실행계획이 완전 바뀌어 버려서 오히려 성능이 안좋아질수도 있기 때문이다. CLUSTER를 도입하면 프로그램 전체를 다 수정해야 한다. 그래서 그 대안으로 SORTING TABLE을 생각 할 수 있다. CLUSTER를 만드는 것이 아니라 TABLE의 DATA를 순서대로 저장하여 CLUSTER를 사용한 듯한 Hit Ratio를 보장받을 수 있도록 하는 방법이다.한 가지 예를 들어보겠다.
보험회사 시스템이 하나 있다. 이 시스템은 GIS 기반의 서비스를 직원들에게 제공한다.
각 대리점 별로 관할 구역이 있고, 각 구역별로 고객들을 관리한다. 대리점별로 당연 구역들은 겹칠 수가 있다. 이것을 최적화한 ERD를 아래와 같이 표현이 가능하다.
한 영업소에서 관리하는 고객 정보를 조회하는데 100여명 밖에 나오지 않는데도 조회시간이 3초가 넘는 시간이 걸렸다. 분명 고객에는 ZIP-CODE로 INDEX가 잡혀있는데도 그랬다. 왜 느릴까 ? 고객 TABLE의 PK는 당연 고객ID가 될 것이다. 하지만 대부분의 JOIN 조건은 ZIP-CODE 이므로 고객ID의 PK가 과연 효율적일까 ? 특정 지역에 사는 100명의 고객을 읽기위해서 100개의 Block을 Random-Single I/O를 한다면 당연 좋은 성능을 기대하기 힘들다. 대부분의 GIS 시스템은 ZIP-CODE 순으로의 ACCESS가 많다. 고객의 PK는 고객ID로 하더라도 물리적인 저장은 ZIP-CODE, 고객ID 순으로 한다면 Hit-Ratio가 훨씬 좋아져서 성능이 향상될 것이라고 생각할 수 있다.
그렇다고 이미 오랫동안 사용중인 SYSTEM에 CLUSTER를 도입하는 것은 위험부담이 너무 크다. 그래서 고객 Table을 물리적으로 ZIP-CODE, 고객ID 순으로 정렬을 해서 넣는 방법을 선택했다.
INSERT INTO A SELECT * FROM B ORDER BY a,b;위와 같은 INSERT SELECT에 ORDER BY가 될까 ? 지금은 된다. Oracle 8.1.6 이후는 가능하지만, 저건 분명 RDBMS의 DATA 순서에 무관한 성질을 위배하는 것이다. 과거에는 INLINE VIEW 에서도 ORDER BY가 안되었다.
CREATE TABLE NEW_CUST UNRECOVERABLE PARALLEL 16 AS SELECT ZIP-CODE, CUST_ID, MIN(a), MIN(b), ... FROM OLD_CUST GROUP BY ZIP-CODE, CUST_ID;요즘은 GROUP BY 와 같은 편법을 안쓰고 그냥 ORDER BY를 써도 된다.
이런식으로 약간의 편법을 이용하여 DATA 자체를 SORTING 하여 저장하는 것을 SORTING TABLE 이라고 한다.
CLUSTER 의 구조
CLUSTER INDEX는 KEY와 그 시작주소만을 가지고 있다.
CLUSTERING TABLE 은 각 CLUSTER KEY 별로 물리적인 CLUSTER로 관리를 한다. CLUSTER는 BLOCK 들의 집합으로 CLUSTER 생성시 그 크기를 지정할수가 있다.
하나의 KEY의 모든 DATA는 CLUSTER에 저장된다. 그러므로 CLUSTER의 크기가 너무 크면, DATA의 수가 적은 KEY에 대해서는 많은 공간이 낭비가 될 것이며, 그렇다고 CLUSTER 크기를 너무 작게 한다면 같은 KEY에 대해서 여기저기에 쪼가리들로 연결되야 하므로 그 효율성이 줄어들 것이다.
CLUSTER 생성시 CLUSTER KEY SIZE PARAMETER가 정말 중요하다. 이 SIZE는 면적으로 생각해야 한다.
1개의 ROW DATA의 평균크기 * KEY별 평균 DATA 수 를 계산해서 Overhead 10% 정도를 추가하여 생성하는게 가장 적당하다.
MULTI-TABLE CLUSTER
전통적인 FILE SYSTEM의 경우는 각 KEY 별로 DATA를 연속적으로 보관하는 경우가 많다. 이것을 DATABASE MODEL로 변경하면서 정규화 1공식. 모든 DATA는 원자화하여 저장한다는 공식을 적용하면서 오른쪽 그림과 같이 2개의 TABLE로 나눠서 저장하게 된다. 하지만 실제로 사용할때는 2개의 TABLE을 늘 JOIN으로 사용한다. (예를 들어서 주문 + 주문내역) 이럴 경우 TABLE은 2개로 나눠져 있더라도 DISK에 같은 공간에 연속적으로 저장되어 있다면 성능을 향상 시킬수 있다. 이때 MULTI-TABLE CLUSTER를 활용하면 된다.
- SELECT 시 엄청난 성능 향상이 기대가 가능하다.
- 하지만 OLTP 환경의 UPDATE, DELETE 등에 대해서는 엄청난 Overhead가 일어나므로 오히려 전체적인 성능을 저하시킬수 있다.
- 절대로 UPDATE, DELETE가 일어나지 않는 환경이라면 도입을 고려해 볼만하다.
* SINGLE-TABLE CLUSTER : INDEX RANGE 때문에 부담이 될 경우에 유용함
* MULTI-TABLE CLUSTER : 정규화에 의해 어쩔수 없이 분할된 TABLE에서 항상 JOIN되기 때문에 물리적으로 한 공간에 둘때 유용함
CLUSTER란 ?
1. 지정된 COLUMN의 순서대로 ROW를 물리적으로 저장시키는 방법이다.
2. 하나 혹은 그 이상의 TABLE을 같은 CLUSTER내에 저장이 가능하다. (MULTI-TABLE CLUSTER)
3. ACCESS 기법이 아니라 ACCESS 효율성을 위한 물리적 저장기법이다.
4. SELECT의 효율을 높여주나 INSERT, UPDATE, DELETE의 부하가 증가된다. (INDEX의 2,3배이상 느림)
5. 분포도가 높을수록 오히려 유리하다. (INDEX의 반대 : INDEX의 단점을 해결 5~7배이상 빠름)
6. 분포도가 넓은 TABLE의 CLUSTERING은 오히려 절약공간이 절약된다. (INDEX에 비해서 KEY의 시작만 가짐)
CLUSTER 선정기준
1. 6 Block 이상의 TABLE
2. 다량의 범위를 자주 ACCESS 하는 경우
3. INDEX를 사용한 처리가 부담이 되는 넓은 분포도를 가지는 경우
4. 여러 개의 TABLE이 비번한 JOIN을 일으킬 때
5. 반복COLUMN이 정규화 작업에 의해 어쩔 수 없이 분할된 경우
6. UNION, DISTINCT, ORDER BY, GROUP BY가 빈번한 COLUMN이면 고려해 볼것 (주로 통계 분석 시스템)
7. 수정이 자주 발생하지 않는 COLUMN
8. 처리범위가 넓어 문제가 발생되는 경우는 SINGLE-TABLE CLUSTERING
9. JOIN이 많아 문제가 발생되는 경우는 MULTI-TABLE CLUSTERING
CLUSTER 고려사항
01. DATA 처리(INSERT, UPDATE, DELETE)에 Overhead 발생 주의
02. INDEX로 충분한 범위는 CLUSTERING 효과가 없음 (Key당 10건 정도 ?)
03. CLUSTER KEY는 수정이 빈번하지 않을 것
04. 각종 ACCESS 형탸에 대해 INDE와 적절한 역할 분담
05. CLUSERING은 기존 INDEX의 수를 감소시킴 (전체적인 INDEX를 재구성 해야함)
06. CLUSTER SIZE PARAMETER가 중요
07. CLUSTER KEY 별로 ROW 수의 편차가 심하지 않을 것
08. CLUSTER에 DATA 입력시 ROW가 적은 TABLE부터 실시할 것
09. CLUSTERING TABLE에 JOIN시 ROW 수의 역순으로 FROM절에 기술할 것 (FROM 절 잴 뒷쪽에)
10. CLUSTERING KEY를 첫번째로 하는 INDEX는 생성하지 말 것
INDEX vs CLUSTER
- INDEX : 해당 INDEX 만큼의 TABLE ACCESS를 반복한다.
- CLUSTER : CLUSTER HEADER를 찾아서 한번에 SCAN
CLUSTER 생성 예제
ANALYZE TABLE MECHUL2T COMPUTE STATISTICS;SELECT AVG_ROW_LEN FROM USER_TABLES WHERE TABLE_NAME = 'MECHUL2T';
SELECT AVG(COUNT(*)) FROM MECHUL2T GROUP Y SALEDATE;
위와 같이 하면 하루 종일 걸린다. 전체 TABLE을 할게 아니라 표본만 몇개 만들어서 하는게 효율적이다.
CREATE CLUSTER MECHUL2# (SALEDATE CHAR(6))
PCTFREE 10 PCTUSED 60 SIZE 3300;
CREATE INDEX MECHUL2#X ON CLUSTER MECHUL2#;
이렇게 해서 CLUSTER TABLE 을 만든다.
RENAME MECHUL2T TO MECHULCT;
이제 테이블 이름을 바꿔준 다음에
CREATE TABLE MECHUL2T (
SALENO VARCHAR2(6) NOT NULL ...
) CLUSTER MECHUL2# (SALEDATE);
TABLE 을 만들면서 TABLE SPACE 대신에 CLUSTER로 지정한다.
INSERT INTO MECHUL2T SELECT * FROM MECHULCT;
DROP TABLE MECHULCT;
CREATE INDEX ...
이제 할일을 해주면 된다.
속도비교
각각의 DATA 들에 대해서 CLUSTER 이용, FULL-SCAN, INDEX-SCAN 시의 속도이다.
CLUSTER 사용 예제
CLUSTER는 Driving 조건으로 사용되어야지 CHECK 조건으로 사용되면 INDEX-SCAN보다 더 느릴수 있다.
CLUSTER가 Driving 될 수 있도록 다른 조건의 다리를 톡 부러트려버려야 된다.
CLUSTER 사용시는 반드시 실행계획을 확인해서 원하는 방향되로 가고 있는지 확인하고,
그렇지 않을때는 수정해 주어야 한다.

댓글 없음:
댓글 쓰기