1. Concurrency의 이해와 C++ Thread의 역사
1998년
그 표준안 중에는
C++98 표준안 이후 13년 만인 2011년에 C++11표준이 만들어 졌습니다.C++11은 C++을 좀 더 쉽고 생산성 높게 만들었습니다.그 표준안 중에는
Multi-threading 도 포함되어 있습니다.C++11에서 재공하는 Thread Library를 사용하면 platform 별로 따로 구현할 필요없이 하나의 code로 모든 platform에서 동일하게 동작하는 Multi-threading program의 개발이 가능합니다.1.1 Concurrency란 ?
둘 이상의 분리된 작업을 동시에 수행하는 것을 뜻합니다.
1.1.1 Computer System에서의 Concurrency
여러 개의 독립적인 작업(task)들을 순서대로(sequential)하게가 아니라 병렬로(parallel) 수행하는 것을 의미합니다.
과거의
Task 여러개를 동시에 수행하게 하더라도 각각의 task를 덩어리(chunk)로 분리하여 번갈아 가면서 수행(task switching)하였습니다.
Single-core CPU에서는 한번에 하나의 task만 수행이 가능했습니다.Task 여러개를 동시에 수행하게 하더라도 각각의 task를 덩어리(chunk)로 분리하여 번갈아 가면서 수행(task switching)하였습니다.
요즘은
이제는 task 들이 정말로 동시에(concurrency) 수행됩니다. 즉,
Multi-core CPU를 대부분 사용합니다.이제는 task 들이 정말로 동시에(concurrency) 수행됩니다. 즉,
hardware concurrency가 지원됩니다.
2개의 tak를 수행하는 경우, 각각의 task는 10개의 chunk로 분리하여 수행한다고 가정했을 경우
하지만
Dual-core CPU에서는 각각의 core가 task를 하나씩 맡아서 수행이 가능합니다.하지만
Single-core CPU에서는 task를 chunk단위로 번갈아 가면서 수행합니다.
task 간에 전환하는 과정을
context switching이라 합니다. context switching을 할때마다 CPU상의 register 상태 (instruction pointer 등...)에 대한 정보를 어딘가에 저장하고 다시 읽어오는 등의 별도 작업 overhead가 발생합니다.
여러 task를 concurrency하게 수행시
예를 들어
hardware thread 개수를 고려하는 것이 좋습니다.예를 들어
Dual-core CPU에서 4개의 task를 수행하게되면 다음 그림과 같이 context switching이 발생합니다.
1.1.2 Concurrency로의 접근
2명의 개발자를 서로 다른 방에서 작업시킬 경우 서로 방해받지 않고 집중해서 작업이 가능하지만, 서로 얘기할게 있을 경우 직접하지 못합니다. 그리고 2개의 방을 관리해야 하며 필요한 업무 메뉴얼이나 각종 비품들을 2개씩 준비해야 합니다.
반면 2명을 한 방에서 같이 작업시킬 경우 얘기할게 있으면 그 자리에서 바로 얘기도 가능하고, 화이트보드 같은 것을 이용해서 공유도 가능합니다. 업무 메뉴얼이나 비품 같은것도 하나씩만 있으면 되고, 사무실도 1개만 관리하면 됩니다. 하지만, 서로의 작업 소음 같은게 방해가 되어 업무의 집중도가 떨어 질 수 있으며, 1개밖에 없는 물건을 같이 쓰면서 어느 한쪽이 기다려야만 하는 상황도 발생합니다.
이 둘의 기본적인 원리는 같습니다.
이 두가지 방법을 적절히 섞어 가면서 concurrency 프로그램을 이용 할줄 알아야 합니다.
반면 2명을 한 방에서 같이 작업시킬 경우 얘기할게 있으면 그 자리에서 바로 얘기도 가능하고, 화이트보드 같은 것을 이용해서 공유도 가능합니다. 업무 메뉴얼이나 비품 같은것도 하나씩만 있으면 되고, 사무실도 1개만 관리하면 됩니다. 하지만, 서로의 작업 소음 같은게 방해가 되어 업무의 집중도가 떨어 질 수 있으며, 1개밖에 없는 물건을 같이 쓰면서 어느 한쪽이 기다려야만 하는 상황도 발생합니다.
Concurrency에 대한 접근도 기본적으로 2가지가 있습니다. 각각의 개발자를 thread로 보면 되고, 사무실을 process로 보면 됩니다. 첫번째 경우는 multiple single-threaded processes 이며, 두번째는 multiple thread in a single process 입니다.이 둘의 기본적인 원리는 같습니다.
이 두가지 방법을 적절히 섞어 가면서 concurrency 프로그램을 이용 할줄 알아야 합니다.
- Multiple process 간의 Concurrency
첫번째 방법은 application을 여러개의 독립된
예를 들면 Web Browser 와 Word Processor를 동시에 띄워놓고 사용하는 경우 같은 것입니다.
이 경우 각각의 Process 간에 공유할 data에 대해서는
single-thread의 process로 나누어서 동시에 실행시키는 방법입니다.예를 들면 Web Browser 와 Word Processor를 동시에 띄워놓고 사용하는 경우 같은 것입니다.
이 경우 각각의 Process 간에 공유할 data에 대해서는
interprocess communication channel을 이용해야 합니다. (signal, socket, file, pipe 등...).
이 방법의 단점은 data 공유를 위한 방법들이 복잡하면서 느립니다.
하지만 장점도 있습니다. process간의 data는 서로 영향을 받지 않으므로 thread 간의 data보다 안전하게 관리가 가능합니다.
각각의 Process를 서로 다른 hardware로 분리하여 network로 연결하는 방법으로의 구축도 쉽습니다. 병렬화(Parallelism)를 이용하여 성능을 향상시키는 것을 보다 효과적으로 할 수 있습니다.
하지만 장점도 있습니다. process간의 data는 서로 영향을 받지 않으므로 thread 간의 data보다 안전하게 관리가 가능합니다.
각각의 Process를 서로 다른 hardware로 분리하여 network로 연결하는 방법으로의 구축도 쉽습니다. 병렬화(Parallelism)를 이용하여 성능을 향상시키는 것을 보다 효과적으로 할 수 있습니다.
- Multiple thread 간의 Concurrency
또 다른 방법으로
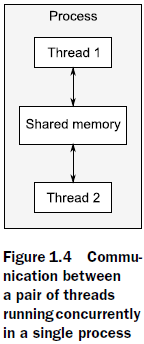
그림 1.4는 같은 메모리를 공유하는 2개의 thread를 설명해줍니다.
같은 메모리 공간안에서 data 보호 수단 없이 사용하려면 그것을 관리하는 것이 multiple process보다는 많은 노력이 필요합니다. 하지만 서로 data를 공유하기는 더 쉽습니다. 여기에 대한 가이드라인은 있으며 이러한 문제들이 극복할수 없는 문제는 아닙니다.
single process에서 multiple thread를 실행시키는 concurrency 방법도 있습니다. Thread는 가벼운 Process라고 생각히시면 됩니다. 각각의 thread 는 독립적으로 동작합니다. 하지만 같은 Process안의 thread 들은 같은 address 공간안에 있으며, 대부분의 data들을 서로 공유하게 됩니다. 그로 인하여 thread 간의 data 관리가 어려우며 충돌 상황이 발생 할 수 있습니다.그림 1.4는 같은 메모리를 공유하는 2개의 thread를 설명해줍니다.
같은 메모리 공간안에서 data 보호 수단 없이 사용하려면 그것을 관리하는 것이 multiple process보다는 많은 노력이 필요합니다. 하지만 서로 data를 공유하기는 더 쉽습니다. 여기에 대한 가이드라인은 있으며 이러한 문제들이 극복할수 없는 문제는 아닙니다.
1.2 Concurreny를 왜 사용할까 ?
Application에서 Concurrency를 사용하는데는 크게 2가지 이유가 있습니다.
관심의 분리 와성능상의 문제가 그 이유 입니다.1.2.1 관심의 분리를 위해 Concurrency를 사용
Software 개발에 있어서 관심의 분리는 항상 고려해야할 만큼 중요합니다. 관계 있는 것끼리 따로 분류하여 개발을 하면 이해하기도 쉽고 test하기도 쉽습니다. 그만큼 bug 발견도 쉬워집니다.
기능별로 따로 작업을 한 경우에는 그것이 같은 시간에 동시에 동작하도록 구현하는게 쉽습니다.
DVD Player Application을 예로 들자면 계속해서 disc에서 data를 읽어서 image 와 sound를 decoding 하여 graphic 과 sound hardware로 전송합니다.
그러면서 사용자의 Pause, Menu, Quit 등의 입력이 있을 경우 그것을 처리해야 합니다.
하나의 thread는 DVD 재생을 담당하고, 다른 thread는 사용자의 입력을 처리하도록 구현을 해야 재생 중에도 사용자의 입력에 대하여 반응이 가능합니다.
기능별로 따로 작업을 한 경우에는 그것이 같은 시간에 동시에 동작하도록 구현하는게 쉽습니다.
DVD Player Application을 예로 들자면 계속해서 disc에서 data를 읽어서 image 와 sound를 decoding 하여 graphic 과 sound hardware로 전송합니다.
그러면서 사용자의 Pause, Menu, Quit 등의 입력이 있을 경우 그것을 처리해야 합니다.
하나의 thread는 DVD 재생을 담당하고, 다른 thread는 사용자의 입력을 처리하도록 구현을 해야 재생 중에도 사용자의 입력에 대하여 반응이 가능합니다.
1.2.2 성능 향상을 위해 Concurrency를 사용
Multiprocessor 시스템은 예전에는 슈퍼컴퓨터나 고사양 서버 시스템 등에만 사용되었지만, 최근에는 일반 PC에서도 single core 보다는 multicore가 많이 사용되어집니다.
각각의 core의 속도가 더이상 많이 빨라지지 않고 대신 여러개의 core를 동시에 수행 할 수 있도록 설계되어져 있습니다.
과거에는 프로그래머가 software를 개발하면, 나중에 더 빠른 process가 나오면 그만큼 software 성능도 같이 향상되었습니다.
하지만 지금은
software가 더 빠른 성능을 내려면 동시에 여러개의 작업들이 수행되도록 설계해야 합니다.
각각의 core의 속도가 더이상 많이 빨라지지 않고 대신 여러개의 core를 동시에 수행 할 수 있도록 설계되어져 있습니다.
과거에는 프로그래머가 software를 개발하면, 나중에 더 빠른 process가 나오면 그만큼 software 성능도 같이 향상되었습니다.
하지만 지금은
Herb Sutter가 말했듯이 "공짜 점심은 끝났습니다."software가 더 빠른 성능을 내려면 동시에 여러개의 작업들이 수행되도록 설계해야 합니다.
Concurrency를 이용하여 성능향상을 시키는데는 2가지 방법이 있습니다.
첫번째는 1개의 task를 여러개로 분리하여 병렬로 실행하여 전체 수행시간을 줄이는 방법이 있습니다.
말은 쉽게 보이지만 각각의 process간에 data의 종속성이 있는 경우에는 구현이 매우 복잡해 질 수 있습니다.
첫번째는 1개의 task를 여러개로 분리하여 병렬로 실행하여 전체 수행시간을 줄이는 방법이 있습니다.
말은 쉽게 보이지만 각각의 process간에 data의 종속성이 있는 경우에는 구현이 매우 복잡해 질 수 있습니다.
이렇게 작업을 분리하는대는 2가지 방법이 있습니다.
- 각각의 작업별로 분리하는 것입니다. 이것을
task parallelism이라 합니다. 서로 다른 알고리즘으로 수행되도록 thread로 분리하는 방법입니다. - data를 분리하는 방법입니다. 이것을
data parallelism이라 합니다. 각각의 thread들이 다른 data를 가지고 같은 알고리즘으로 동작하는 방법입니다.
쉽게 병렬화가 되는 알고리즘을
이게 나쁜 의미의 처치 곤란이 아니라 갑자기 많은 부를 가졌을 경우의 처치 곤란할 정도의 많은 돈이 있다는 그런 뉘앙스라고 합니다.
이건 Scalability 능력이 좋은 알고리즘이라서, 사용가능한 hardware thread 가 늘어나면, 알고리즘의 병렬화도 그만큼 늘어납니다.
"백지장도 맞들면 낫다." 라는 속담과 완벽하게 맞아 떨어지는 방식입니다.
task를 고정된 수의 병렬화로 나눈 (scalable하지 않은) 알고리즘은 처치곤란 알고리즘이 아닙니다.
처치 곤란 병렬 (embarrassingly parallel) 이라고 부릅니다.이게 나쁜 의미의 처치 곤란이 아니라 갑자기 많은 부를 가졌을 경우의 처치 곤란할 정도의 많은 돈이 있다는 그런 뉘앙스라고 합니다.
naturally parallel 또는 conveniently concurrent 라고 부르기도 합니다.이건 Scalability 능력이 좋은 알고리즘이라서, 사용가능한 hardware thread 가 늘어나면, 알고리즘의 병렬화도 그만큼 늘어납니다.
"백지장도 맞들면 낫다." 라는 속담과 완벽하게 맞아 떨어지는 방식입니다.
task를 고정된 수의 병렬화로 나눈 (scalable하지 않은) 알고리즘은 처치곤란 알고리즘이 아닙니다.
성능향상을 위해 concurrency를 사용하는 두번째 방법은 보다 큰 문제를 병렬화하는 것입니다.
한번에 1개의 file을 처리하는 것 보다는 2개,10개,20개의 파일을 처리하는 것입니다.
진정한 의미의 data 병렬화구조의 application 입니다.
여전히 하나의 chunk를 처리하는데 걸리는 시간은 동일하지만, 여러 세트를 동시에 수행하여 예전에는 불가능했던 일이 가능하게 되었습니다.
예를 들어서 video processing 에서 각각의 영역별로 병렬로 처리가 가능하게 됨으로서 훨씬 더 큰 해상도의 처리가 가능해 졌습니다.
한번에 1개의 file을 처리하는 것 보다는 2개,10개,20개의 파일을 처리하는 것입니다.
진정한 의미의 data 병렬화구조의 application 입니다.
여전히 하나의 chunk를 처리하는데 걸리는 시간은 동일하지만, 여러 세트를 동시에 수행하여 예전에는 불가능했던 일이 가능하게 되었습니다.
예를 들어서 video processing 에서 각각의 영역별로 병렬로 처리가 가능하게 됨으로서 훨씬 더 큰 해상도의 처리가 가능해 졌습니다.
1.2.3 Concurrency를 사용하면 안될 때
Concurrency를 사용하면 안될 때를 아는 것은 언제 사용해야 하는가 만큼이나 중요합니다.
기본적으로 Concurrency를 사용하면 안되는 유일한 이유는
Concurrency를 사용한 Code는 대부분 이해하기가 어렵기 때문에 작성 및 유지보수가 훨씬 복잡합니다.
그리고 bug를 유발할 가능성도 더 커지며, bug를 잡는것 또한 더 힘듭니다. 멀티쓰레드를 위한 추가 개발 시간과 그 유지보수의 추가 비용보다 성능 이익이 충분히 크지 않다면 Concurrency를 사용하는 의미가 크게 없습니다.
기본적으로 Concurrency를 사용하면 안되는 유일한 이유는
사용해도 별 이익이 없는 경우입니다.Concurrency를 사용한 Code는 대부분 이해하기가 어렵기 때문에 작성 및 유지보수가 훨씬 복잡합니다.
그리고 bug를 유발할 가능성도 더 커지며, bug를 잡는것 또한 더 힘듭니다. 멀티쓰레드를 위한 추가 개발 시간과 그 유지보수의 추가 비용보다 성능 이익이 충분히 크지 않다면 Concurrency를 사용하는 의미가 크게 없습니다.
그리고 예상한 만큼 성능향상이 나지 않을 수도 있다는 것을 고려해야 합니다.
Thread를 생성하고 수행하는데는 오버해드가 발생합니다.
OS의 스케줄러에서 thread 실행을 위하여 커널 리소스 및 stack 공간을 할당하고 thread 간의
또한 thread는 한정된 자원입니다. 너무 많은 thread를 생성하게 되면 시스템 전체를 느리게 할 수도 있습니다.
각각의 thread는 별도의 메모리 공간을 할당 받게 되므로 사용가능한 메모리를 많이 소비하게 됩니다.
32bit 환경에서는 메모리 최대 한도가 4GB라서 더더욱 조심해야 합니다.
64bit에서는 메모리 주소상의 제한은 없지만 하드웨어 상으로 메모리는 제한된 자원이므로 관리가 중요합니다.
Thread pool을 이용하여 관리하면 어느 정도 해결이 가능하지만, 이 세상에 만능 특효약은 없습니다. (silver bullet) Client/Server application에서 Server에서 client의 접속을 각각의 thread로 서비스를 제공한다면, 접속자수가 적을 때는 상관이 없지만, 접속자가 많아지면 server의 자원은 금방 고갈될 것입니다.
Thread를 생성하고 수행하는데는 오버해드가 발생합니다.
OS의 스케줄러에서 thread 실행을 위하여 커널 리소스 및 stack 공간을 할당하고 thread 간의
context switching을 할때마다 자원들을 save & load 하는 과정이 필요합니다.또한 thread는 한정된 자원입니다. 너무 많은 thread를 생성하게 되면 시스템 전체를 느리게 할 수도 있습니다.
각각의 thread는 별도의 메모리 공간을 할당 받게 되므로 사용가능한 메모리를 많이 소비하게 됩니다.
32bit 환경에서는 메모리 최대 한도가 4GB라서 더더욱 조심해야 합니다.
64bit에서는 메모리 주소상의 제한은 없지만 하드웨어 상으로 메모리는 제한된 자원이므로 관리가 중요합니다.
Thread pool을 이용하여 관리하면 어느 정도 해결이 가능하지만, 이 세상에 만능 특효약은 없습니다. (silver bullet) Client/Server application에서 Server에서 client의 접속을 각각의 thread로 서비스를 제공한다면, 접속자수가 적을 때는 상관이 없지만, 접속자가 많아지면 server의 자원은 금방 고갈될 것입니다.
이 경우 thread pool을 이용하여 최적화된 성능을 보장 할 수 있는데 뒤에서 설명 드리겠습니다. (챕터 9)
성능 향상을 위한 Concurrency의 사용은 다른 최적화 전략과 유사합니다.
성능을 향상 시켜주지만, code를 복잡게 하고, 버그를 유발할 가능성을 크게 합니다.
따라서 성능 향상이 중요한 application에서는 충분히 고려를 해서 도입을 해야 합니다.
물론 편리성을 위해서 UI와 background에서 진행되어야 할 작업을 분리하는 것에도 multi-thread 디자인을 사용하면 유용합니다.
성능을 향상 시켜주지만, code를 복잡게 하고, 버그를 유발할 가능성을 크게 합니다.
따라서 성능 향상이 중요한 application에서는 충분히 고려를 해서 도입을 해야 합니다.
물론 편리성을 위해서 UI와 background에서 진행되어야 할 작업을 분리하는 것에도 multi-thread 디자인을 사용하면 유용합니다.
1.3 C++ 에서의 Concurrency 와 multi-threading
C++11에서는 표준화된 multi-threading 을 제공해 주므로, 이제 더이상 특정 플랫폼에 의존적인 multi-thread code를 작성할 필요가 없습니다.
어떻게 C++ thread library가 표준으로 정해졌는지를 알기 위해서 그 동안 C++에서의 multi-thread의 역사를 한번 살표 보도록 하겠습니다.
어떻게 C++ thread library가 표준으로 정해졌는지를 알기 위해서 그 동안 C++에서의 multi-thread의 역사를 한번 살표 보도록 하겠습니다.
1.3.1 C++에서의 multi-thread 역사
C++98 표준에서는 thread 사용에 대해서 고려하지 않고 sequential code에 대한 요소만을 고려하였습니다.
뿐만 아니라 메모리 모델이 공식적으로 정의되지 않아서 C++98 표준안과는 별게로 multi-thread 관련 요소들을 compiler 별로 정의해야만 했습니다.
그래서 플랫폼 별로 각각 다른 multi-thread 기능 사용이 가능한 API들을 생성하였습니다.
그러다 MFC, Boost, ACE 등에서 플랫폼 별 API를 래핑하여 multi-thread 사용을 좀 더 편리하게 사용할수 있도록 제공해주는 작업을 진행했습니다.
각 library의 세부 사항은 달랐지만, 사용법에 대해서는 유사한 점이 많았습니다. 특히 mutex 와 lock 관련하여서는
뿐만 아니라 메모리 모델이 공식적으로 정의되지 않아서 C++98 표준안과는 별게로 multi-thread 관련 요소들을 compiler 별로 정의해야만 했습니다.
그래서 플랫폼 별로 각각 다른 multi-thread 기능 사용이 가능한 API들을 생성하였습니다.
그러다 MFC, Boost, ACE 등에서 플랫폼 별 API를 래핑하여 multi-thread 사용을 좀 더 편리하게 사용할수 있도록 제공해주는 작업을 진행했습니다.
각 library의 세부 사항은 달랐지만, 사용법에 대해서는 유사한 점이 많았습니다. 특히 mutex 와 lock 관련하여서는
RAII (Resource Acquisition Is Initialization) 기법을 사용하여 좀 더 편리하게 사용할 수 있도록 하였습니다.
대부분의 경우 multi-thread를 지원하는 C++ 컴파일러들은 플랫폼에 의존적인 API와 플랫폼에 독립적인 class library로 구성되었습니다.
그 결과 multi-thread application 들이 많이 생겨나기 시작했습니다.
하지만 메모리 모델의 표준정립이 없으므로 플랫폼별로 multi-thread code도 달라야만 해서 다른 hardware에 동작하도록 cross-platform code 작업에는 많은 비용이 발생해야 했습니다.
그 결과 multi-thread application 들이 많이 생겨나기 시작했습니다.
하지만 메모리 모델의 표준정립이 없으므로 플랫폼별로 multi-thread code도 달라야만 해서 다른 hardware에 동작하도록 cross-platform code 작업에는 많은 비용이 발생해야 했습니다.
1.3.2 표준으로 Concurrency 지원
C++11 표준 재정으로 이 모든 것이 변했습니다. thread를 인식하는 메모리 모델 뿐만 아니라 thread를 관리하는 class, 공유 data 보호, thread 간의 동기화연산, atomic 연산에 대해서도 표준화 했습니다.
새로운 C++ Thread Library는
새로운 C++ Thread Library는
Boost Thread Library의 영향을 크게 받았습니다.1.3.3 C++ Thread Library의 효율성
C++ 표준의 thread library는 low-level 요소들을 래핑하여 제공을 해 줍니다.
그러므로 당연히
그러므로 당연히
추상화 비용 (Abstraction penalty)에 대해서 생각하지 않을 수 없습니다.
Abstraction penalty 란 추상화를 해서 구현을 하면 좀 더 일반적인 상황에 대한 고려를 해야하므로 특정 상황에서 최적의 성능을 발휘하는 code에 비해서 상대적으로 속도, 메모리, 실행파일 크기 등에서 어느 정도 오버해드가 발생 할수 밖에 없나는 뜻입니다.
그래서 C++ 표준위원들은 이 점을 고려하여 설계하려고 노력을 많이 하였습니다.
low-level API를 직접 사용하는거와 거의 비슷한 성능을 내도록 설계하였습니다.
이 library는 대부분의 주요 플랫폼에서 효율적으로 구현이 가능하도록 설계되었습니다. (추상화 비용을 매우 낮추도록 노력하였습니다.)
또다른 C++ 표준위원회의 목표는 기계어 수준에 가까울 정도의 성능을 내는 것이었습니다.
그래서 새로운 메모리 모델과 함께 bit, byte 단위로 직접 제어와 thread 간의 동기화 및 가시성을 위한 atomic 연산을 내놓았습니다.
예전에는 각 플랫폼별 어셈블리 언어에 맞게끔 다르게 사용했지만, 이젠 어디에서나 동일하게 사용이 가능합니다.
새로운 표준 타입을 사용하면 더 쉽게 개발 및 유지보수가 가능하며, 여러 플랫폼에서 사용이 가능합니다.
low-level API를 직접 사용하는거와 거의 비슷한 성능을 내도록 설계하였습니다.
이 library는 대부분의 주요 플랫폼에서 효율적으로 구현이 가능하도록 설계되었습니다. (추상화 비용을 매우 낮추도록 노력하였습니다.)
또다른 C++ 표준위원회의 목표는 기계어 수준에 가까울 정도의 성능을 내는 것이었습니다.
그래서 새로운 메모리 모델과 함께 bit, byte 단위로 직접 제어와 thread 간의 동기화 및 가시성을 위한 atomic 연산을 내놓았습니다.
예전에는 각 플랫폼별 어셈블리 언어에 맞게끔 다르게 사용했지만, 이젠 어디에서나 동일하게 사용이 가능합니다.
새로운 표준 타입을 사용하면 더 쉽게 개발 및 유지보수가 가능하며, 여러 플랫폼에서 사용이 가능합니다.
C++ 표준위원회는 multi-thread code를 좀 더 쉽고 오류가 덜 나도록 사용할 수 있도록 높은 수준의 추상화를 제공합니다.
대부분의 경우 표준화된 library 만으로 성능과 편리성을 모두 만족시켜 줄 수 있지만, 이게 플랫폼별 API보다 성능이 더 뛰어나다고는 말할수 없습니다.
특별한 경우에 대해서는 플랫폼 별 기능을 사용해야 할 수도 있습니다.
대부분의 경우 표준화된 library 만으로 성능과 편리성을 모두 만족시켜 줄 수 있지만, 이게 플랫폼별 API보다 성능이 더 뛰어나다고는 말할수 없습니다.
특별한 경우에 대해서는 플랫폼 별 기능을 사용해야 할 수도 있습니다.
1.3.4 플랫폼 별 기능
C++ 쓰레드 라이브러리는 멀티스레딩 및 Concurrency에 대한 거의 모든 기능들을 제공하지만, 거기에는 없는 각 플랫폼 별 기능들이 있을 수 있습니다.
C++ 쓰레드 라이브러리는 각 플랫폼별 API를 제어할 수 있도록
이 책에서
물론 플랫폼별 기능을 사용하는것을 고려하기 전에 표준 라이브러리가 제공하는 것을 이해하고 활용하는 것이 더 중요합니다.
C++ 쓰레드 라이브러리는 각 플랫폼별 API를 제어할 수 있도록
native_handle()를 제공합니다.이 책에서
native_handle()을 이용한 조작은 설명되지 않을 것입니다.물론 플랫폼별 기능을 사용하는것을 고려하기 전에 표준 라이브러리가 제공하는 것을 이해하고 활용하는 것이 더 중요합니다.
1.4 시작하기
C++11 호환 컴파일러를 준비합니다.
1.4.1 Hello Concurrenct World
간단한 Hello World 예제를 한번 보겠습니다.
#include <iostream>
void main()
{
std::cout << "Hello World\n";
}
이것을 Hello, Concurrenct World와 비교해 보겠습니다.
#include <iostream>
#include <thread> // 1. thread header 추가
void hello() // 2. output 부분을 별도 function으로 구현
{
std::cout << "Hello World\n";
}
void main()
{
std::thread t(hello); // 3. thread 생성
t.join(); // 4. thread 종료를 기다림
}
다른 점:
thread를 include 했습니다. C++ 멀티스레딩을 제공하는 함수와 class들은 thread에서 제공합니다. 공유 데이터를 보호하는 것은 다른 헤더파일에 있습니다.- 메세지를 출력하는 것을 별도의 함수로 구현했습니다. 왜냐면 모든 스레드를 실행하기 위해서는 초기화 함수가 필요합니다. 응용 프로그램의 초기 쓰레드는
main()이지만, 다른 모든 스레드는std::thread의 객체의 생성자로부터 생성됩니다. 여기서는 t라는 이름의 std::thread 객체가hello()함수를 초기화 함수로 가집니다. - main()에서 바로 hello() 함수를 호출하는것과는 달리 새로운 스레드를 만듭니다. 즉 main()과 hello()의 2개의 스레드가 실행되게 됩니다. 새로운 스레드를 가동시킨 후 기존 스레드는 계속해서 실행됩니다. 새로운 스레드가 종료될때까지 기다리지 않는다면 main()가 끝까지 다 실행되고 나면 새로운 스레드가 실행되기 전일지라도 프로그램은 종료하게 됩니다. 그것을 막기 위해서
join()을 호출하여 hello() 스레드가 종료될때까지 기다리게 하였습니다.
댓글 없음:
댓글 쓰기